1、资源指标和资源监控
一个集群系统管理离不开监控,同样的Kubernetes也需要根据数据指标来采集相关数据,从而完成对集群系统的监控状况进行监测。这些指标总体上分为两个组成:监控集群本身和监控Pod对象,通常一个集群的衡量性指标包括以下几个部分:
- 节点资源状态:主要包括网络带宽、磁盘空间、CPU和内存使用率
- 节点的数量:即时性了解集群的可用节点数量可以为用户计算服务器使用的费用支出提供参考。
- 运行的Pod对象:正在运行的Pod对象数量可以评估可用节点数量是否足够,以及节点故障时是否能平衡负载。
另一个方面,对Pod资源对象的监控需求大概有以下三类:
- Kubernetes指标:监测特定应用程序相关的Pod对象的部署过程、副本数量、状态信息、健康状态、网络等等。
- 容器指标:容器的资源需求、资源限制、CPU、内存、磁盘空间、网络带宽的实际占用情况。
- 应用程序指标:应用程序自身的内建指标,和业务规则相关
2、Weave Scope监控集群
Weave Scope 是 Docker 和 Kubernetes 可视化监控工具。Scope 提供了至上而下的集群基础设施和应用的完整视图,用户可以轻松对分布式的容器化应用进行实时监控和问题诊断。 对于复杂的应用编排和依赖关系,scope可以使用清晰的图标一览应用状态和拓扑关系。
(1)Weave Scope部署
[root@k8s-master mainfests]# kubectl apply -f "https://cloud.weave.works/k8s/scope.yaml?k8s-version=$(kubectl version | base64 | tr -d '\n')"
namespace/weave created #创建名称空间weave,也可以在创建时指定名称空间
serviceaccount/weave-scope created #创建serviceaccount
clusterrole.rbac.authorization.k8s.io/weave-scope created
clusterrolebinding.rbac.authorization.k8s.io/weave-scope created
deployment.apps/weave-scope-app created #创建deployment
service/weave-scope-app created #创建service
daemonset.extensions/weave-scope-agent created #创建deamonset
[root@k8s-master mainfests]# kubectl get ns
NAME STATUS AGE
default Active 68d
ingress-nginx Active 28d
kube-public Active 68d
kube-system Active 68d
weave Active 1m
[root@k8s-master mainfests]# kubectl get deployment -n weave
NAME READY UP-TO-DATE AVAILABLE AGE
weave-scope-app 1/1 1 1 73s
weave-scope-cluster-agent 1/1 1 1 66s
[root@k8s-master mainfests]# kubectl get svc -n weave
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
weave-scope-app ClusterIP 10.105.0.119 <none> 80/TCP 119s
[root@k8s-master mainfests]# kubectl get pod -n weave
NAME READY STATUS RESTARTS AGE
weave-scope-agent-b6crx 0/1 ContainerCreating 0 2m
weave-scope-agent-wlnff 1/1 Running 0 2m
weave-scope-agent-xws78 1/1 Running 0 2m
weave-scope-app-b965dccb7-gbcrg 1/1 Running 0 2m8s
weave-scope-cluster-agent-6598584d8-lqd9h 1/1 Running 0 2m1s
- DaemonSet weave-scope-agent,集群每个节点上都会运行的 scope agent 程序,负责收集数据。
- Deployment
weave-scope-app,scope 应用,从 agent 获取数据,通过 Web UI 展示并与用户交互。 - Service
weave-scope-app,默认是 ClusterIP 类型,为了方便已通过kubectl edit修改为NodePort。
[root@k8s-master mainfests]# kubectl edit svc/weave-scope-app -n weave
将service的type改为NodePort
service/weave-scope-app edited
[root@k8s-master mainfests]# kubectl get svc -n weave
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
weave-scope-app NodePort 10.105.0.119 <none> 80:30890/TCP 3m51
(2)使用 Scope
浏览器访问 http://IP:30890/,Scope 默认显示当前所有的 Controller(Deployment、DaemonSet 等)。
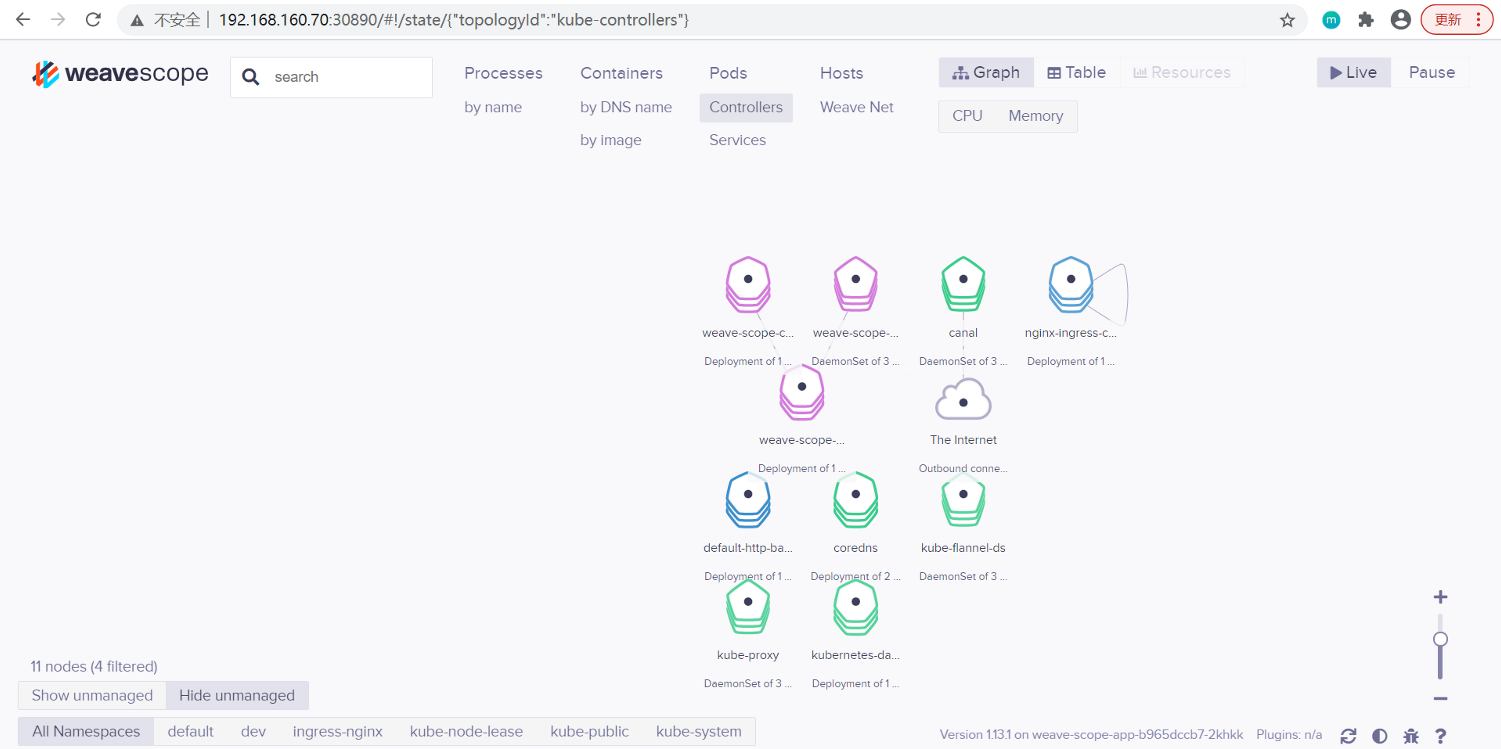
(3)拓扑结构
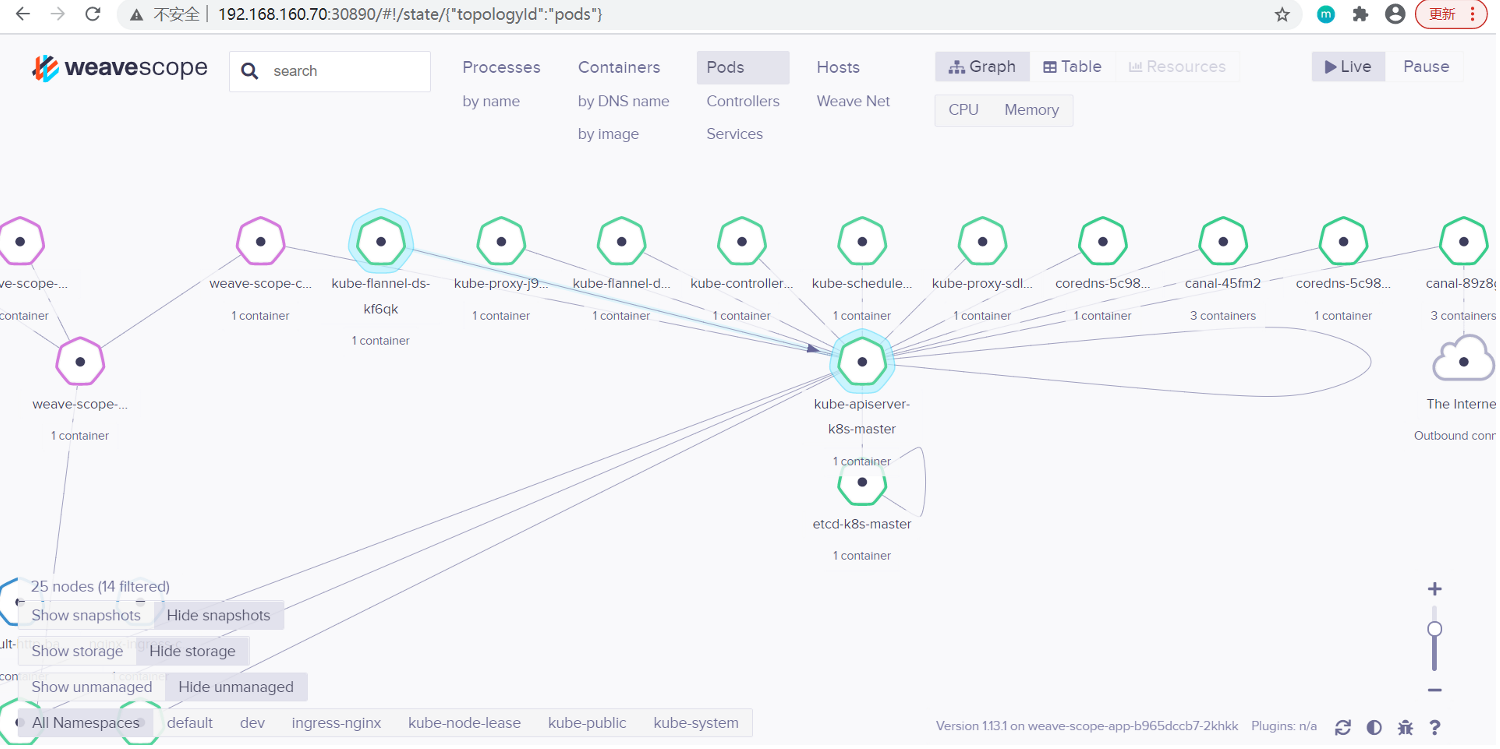
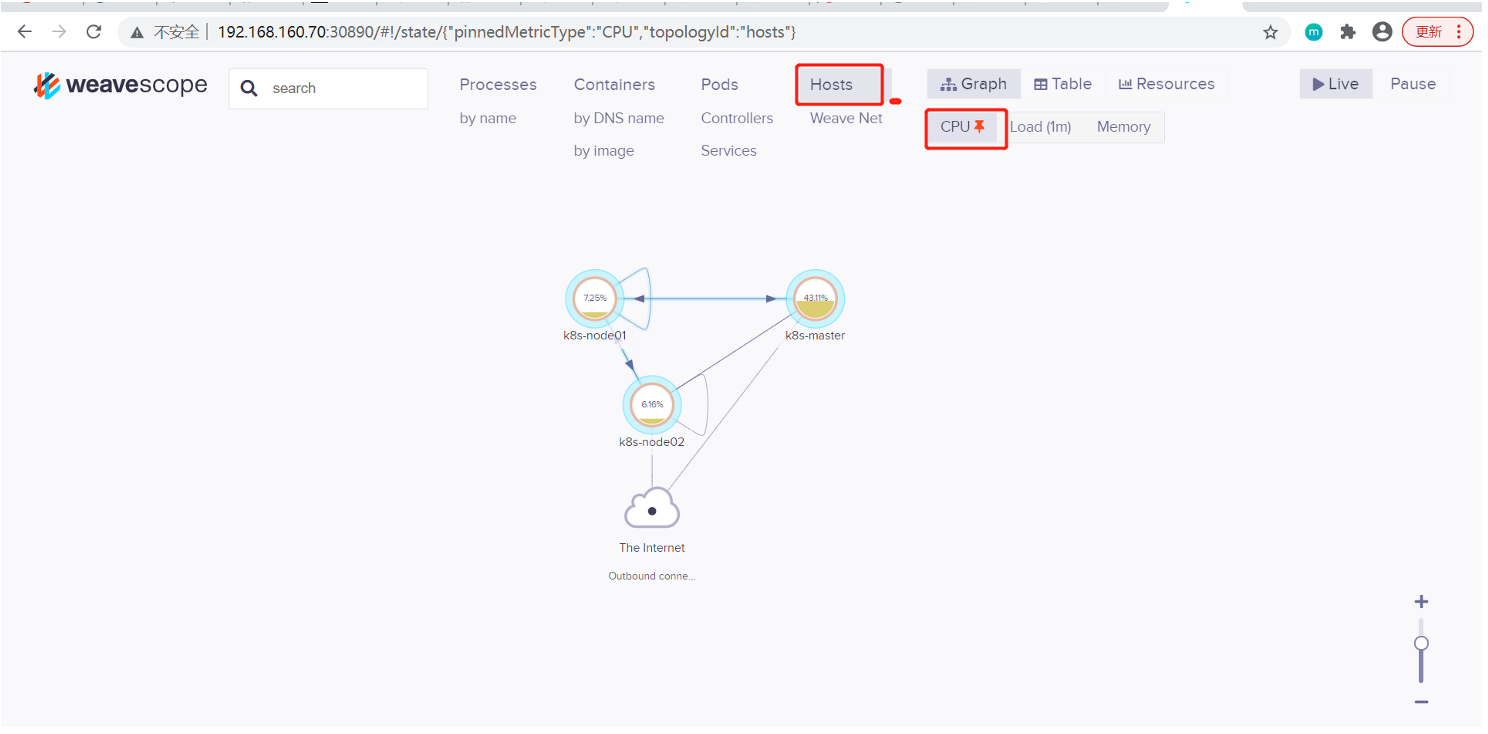
Scope 会自动构建应用和集群的逻辑拓扑。比如点击顶部 PODS,会显示所有 Pod 以及 Pod 之间的依赖关系。
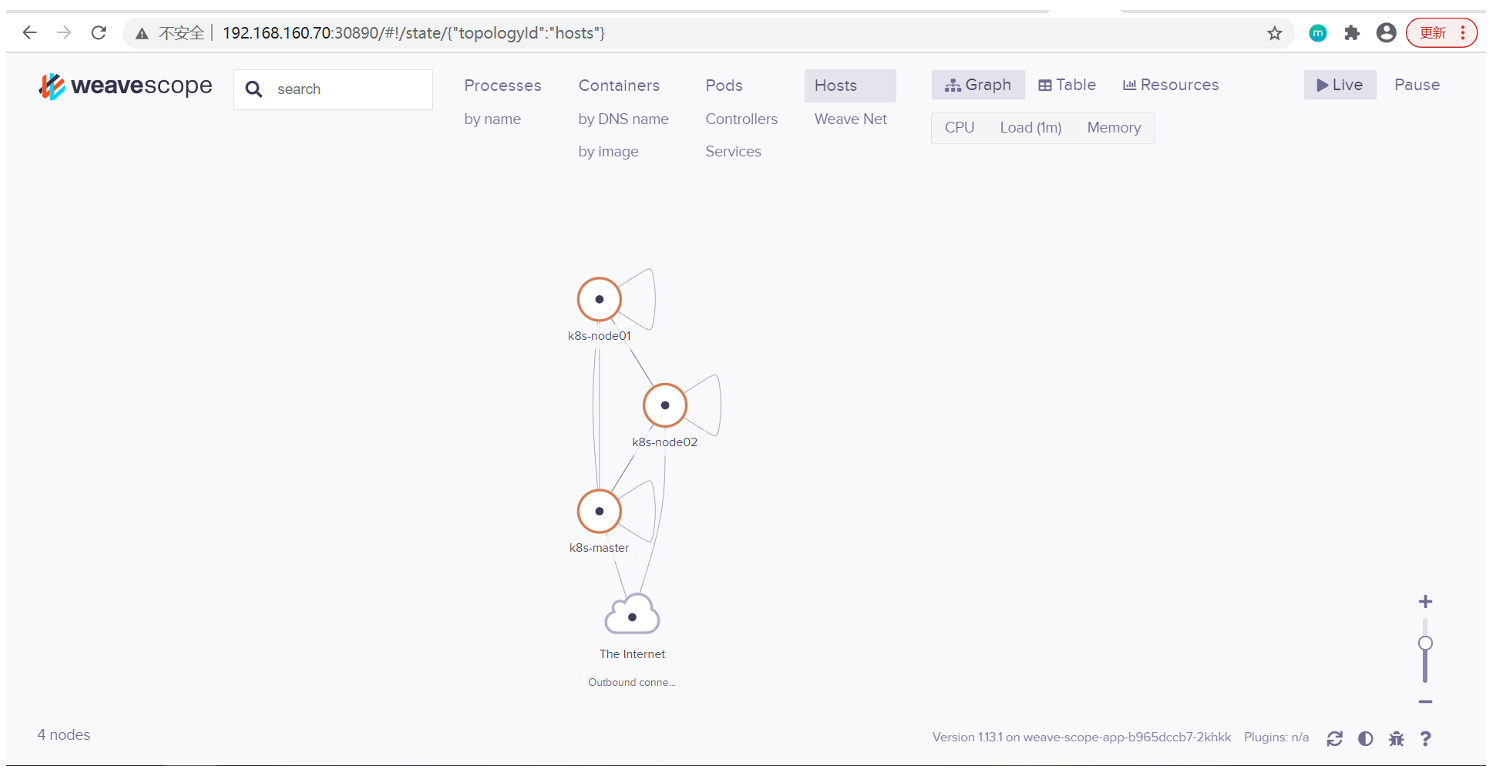
点击 HOSTS,会显示各个节点之间的关系。
(4)实时资源监控
可以在 Scope 中查看资源的 CPU 和内存使用情况。 支持的资源有 Host、Pod 和 Container。
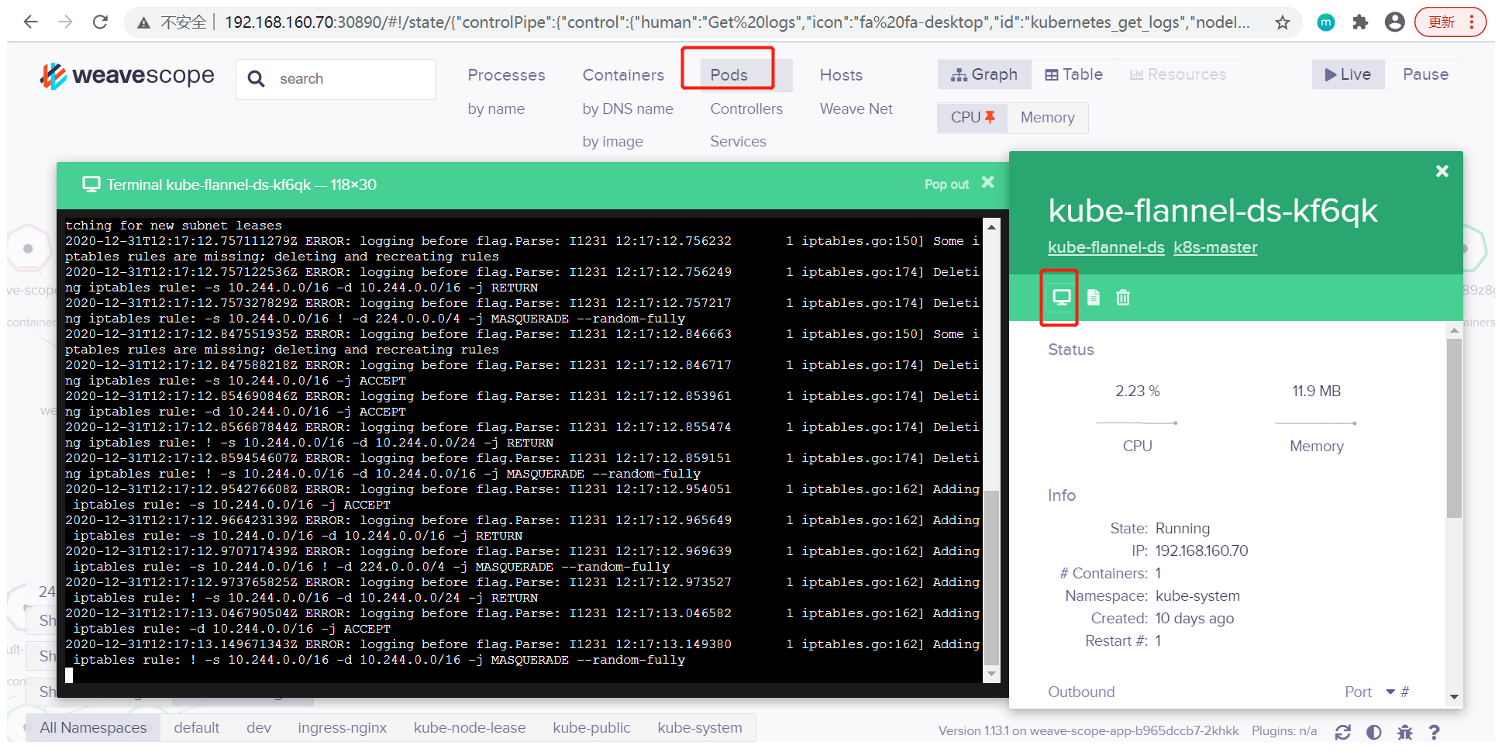
(5)在线操作
可以查看 Pod 的日志:
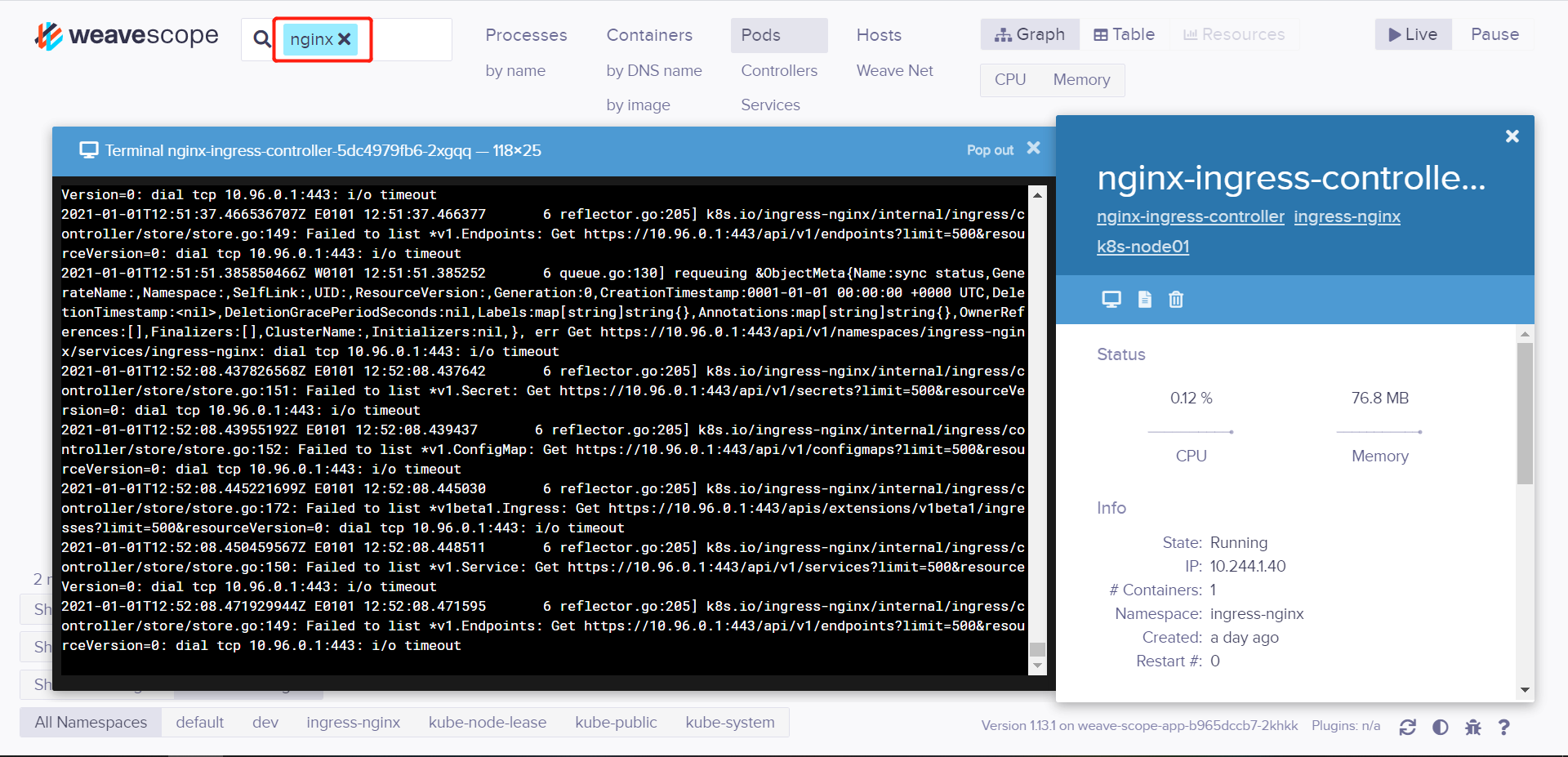
(6)强大的搜索功能
Scope 支持关键字搜索和定位资源。
3、HPA(Horizontal Pod Autoscaler)
HPA(Horizontal Pod Autoscaler)Pod自动弹性伸缩,K8S通过对Pod中运行的容器各项指标(CPU占用、内存占用、网络请求量)的检测,实现对Pod实例个数的动态新增和减少。
早期的kubernetes版本,只支持CPU指标的检测,因为它是通过kubernetes自带的监控系统heapster实现的。
到了kubernetes 1.8版本后,heapster已经弃用,资源指标主要通过metrics api获取,这时能支持检测的指标就变多了(CPU、内存等核心指标和qps等自定义指标)
1版本测试
[root@k8s-master ~]# kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=1 --requests='cpu=50m,memory=256Mi' --limits='cpu=50m,memory=256Mi' --labels='app=myapp' --expose --port=80
[root@k8s-master ~]# kubectl autoscale deployment myapp --min=1 --max=8 --cpu-percent=60 //最小1个副本,最大8个副本,cpu使用达到60%开始扩容
horizontalpodautoscaler.autoscaling/myapp autoscaled
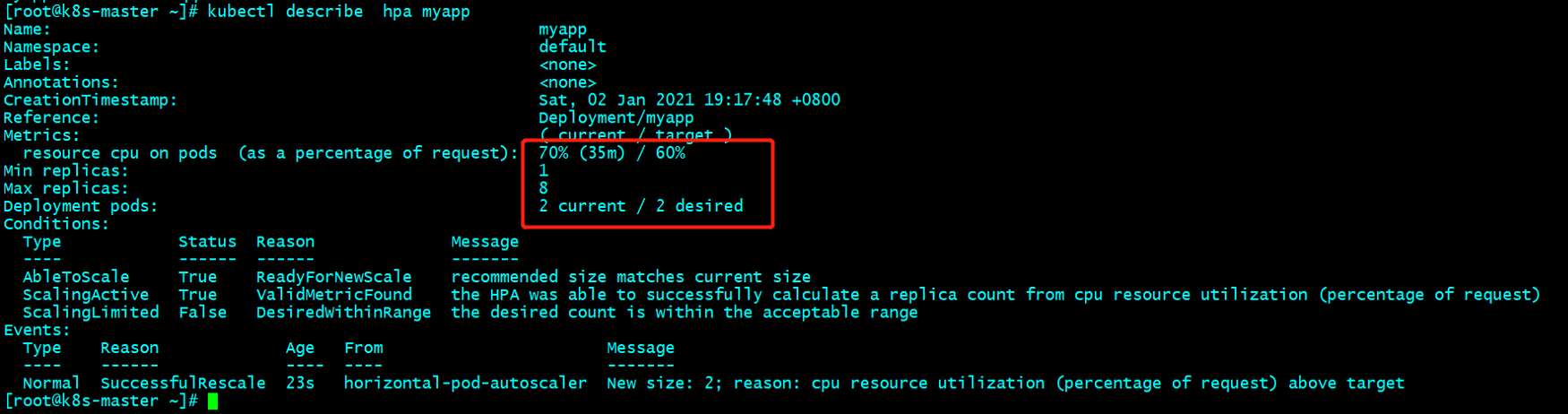
[root@k8s-master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp Deployment/myapp <unknown>/60% 1 8 0 4s
[root@k8s-master ~]# kubectl patch svc myapp -p '{"spec":{"type":"NodePort"}}'
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 40d
myapp NodePort 10.106.222.204 <none> 80:31232/TCP 143m
通过ab进行压力测试效果
[root@k8s-node02 ~]# ab -c 100 -n 500000 http://192.168.160.70:31232/index.html

2版本测试
该版本支持内存高后扩容和缩容
[root@k8s-master metrics-server]# kubectl delete hpa myapp
[root@k8s-master metrics-server]# vim hpa-v2-demo.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-v2
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 55
- type: Resource
resource:
name: memory
targetAverageValue: 50Mi
[root@k8s-master metrics-server]# kubectl apply -f hpa-v2-demo.yaml
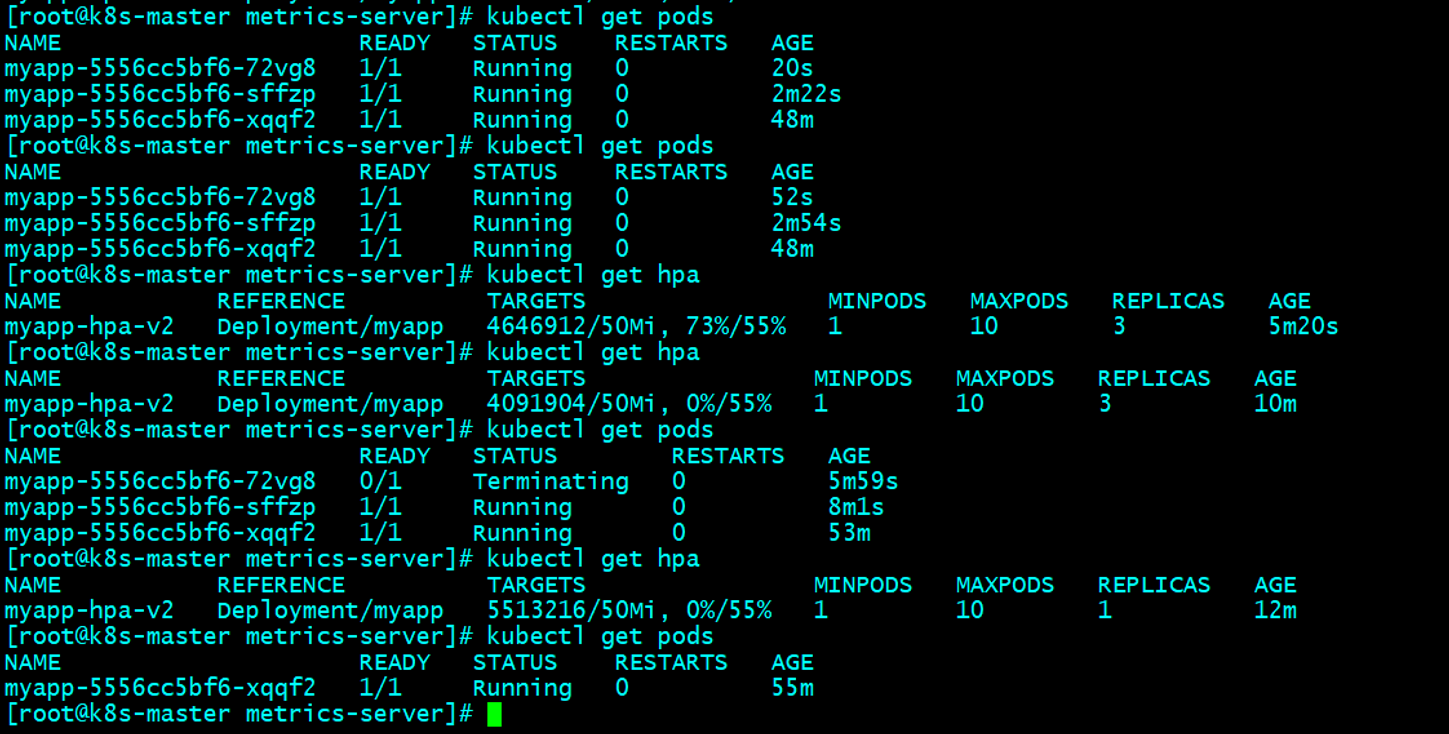
[root@k8s-master metrics-server]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-hpa-v2 Deployment/myapp <unknown>/50Mi, <unknown>/55% 1 10 0 13s
[root@k8s-node02 ~]# ab -c 100 -n 500000 http://192.168.160.70:31232/index.html 测试
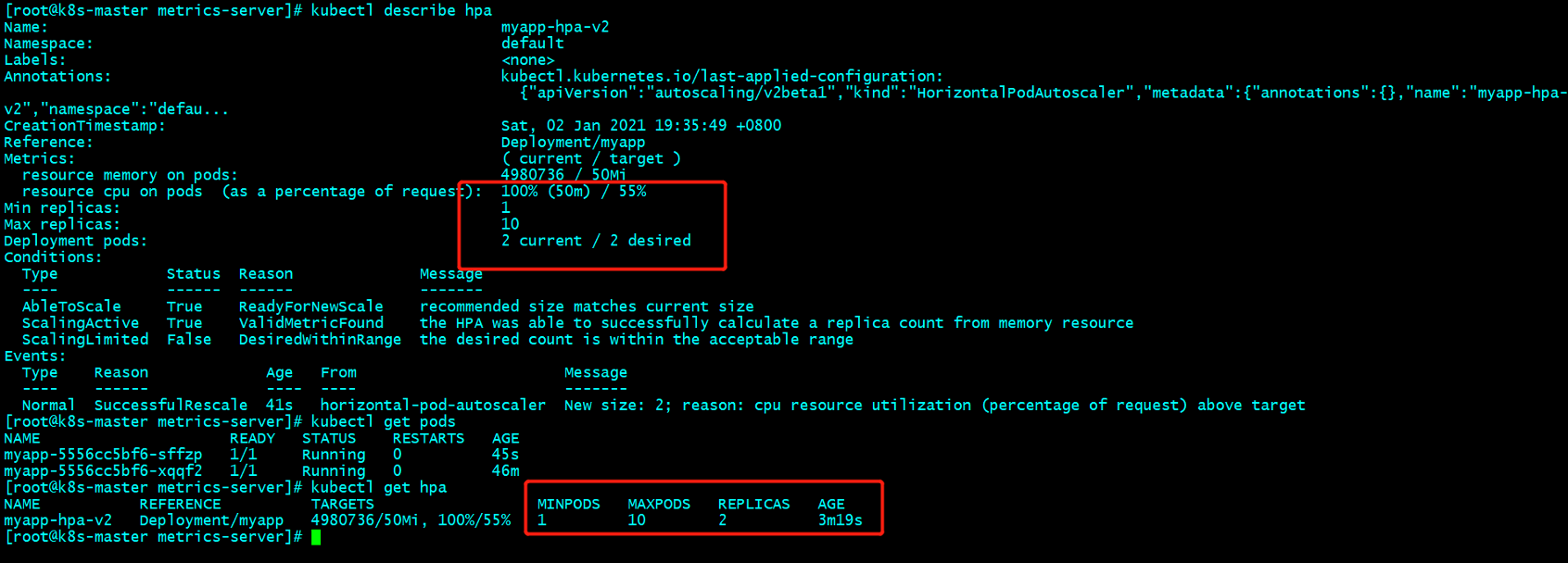
如果使用率降到了阈值,副本也会自动回收,有一个等待时长,需要点时间