
问题现象
- 客户端访问对端服务器端口,时通时不通
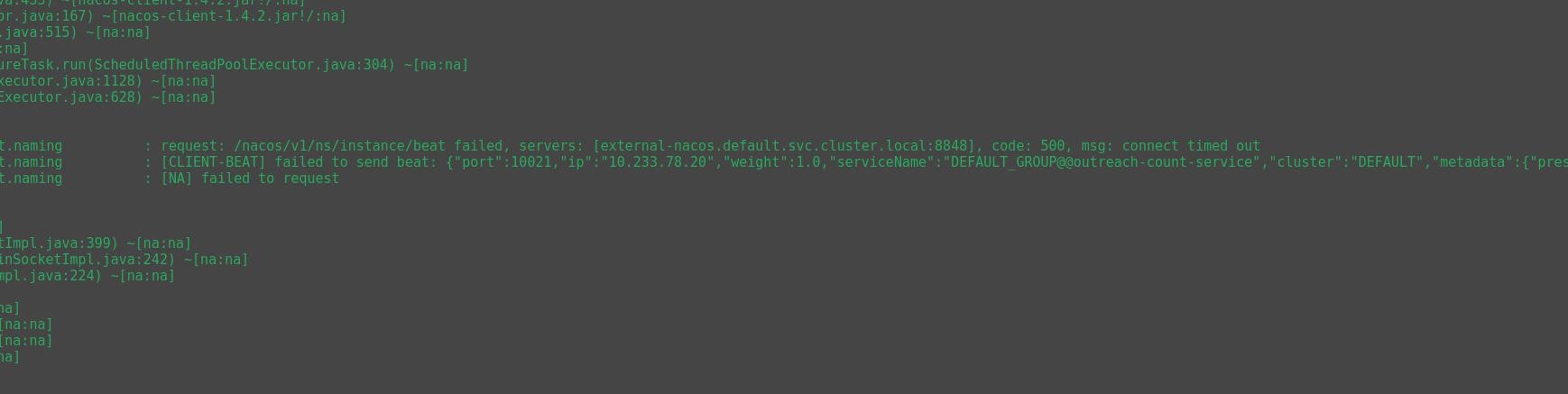 多数服务出现连接nacos 500问题
多数服务出现连接nacos 500问题

- 客户端通过nacos访问配置,获取到的配置地址为其他集群的地址
排查记录
- 检查服务到nacos的连接是否正常
- 通过进入到容器当中,去ping
external-nacos.default.svc.cluster.local可ping通
- 通过进入到容器当中,去ping
- 排查 nacos 状态,检查nacos是否正常
- 所有的中间件连接信息,均是通过nacos配置中心来获取配置
- kubectl get ep external-nacos
- 逐一访问 endpoint 均正常
- 客户端telnet数据库端口,发现时通时不通
- 检查k8s 集群 cni mtu 发现,值为1430,初步怀疑是服务与应用交互的数据包过大,导致的超时,尝试修改cni插件的MTU值为1480。一般比物理网卡小20即可
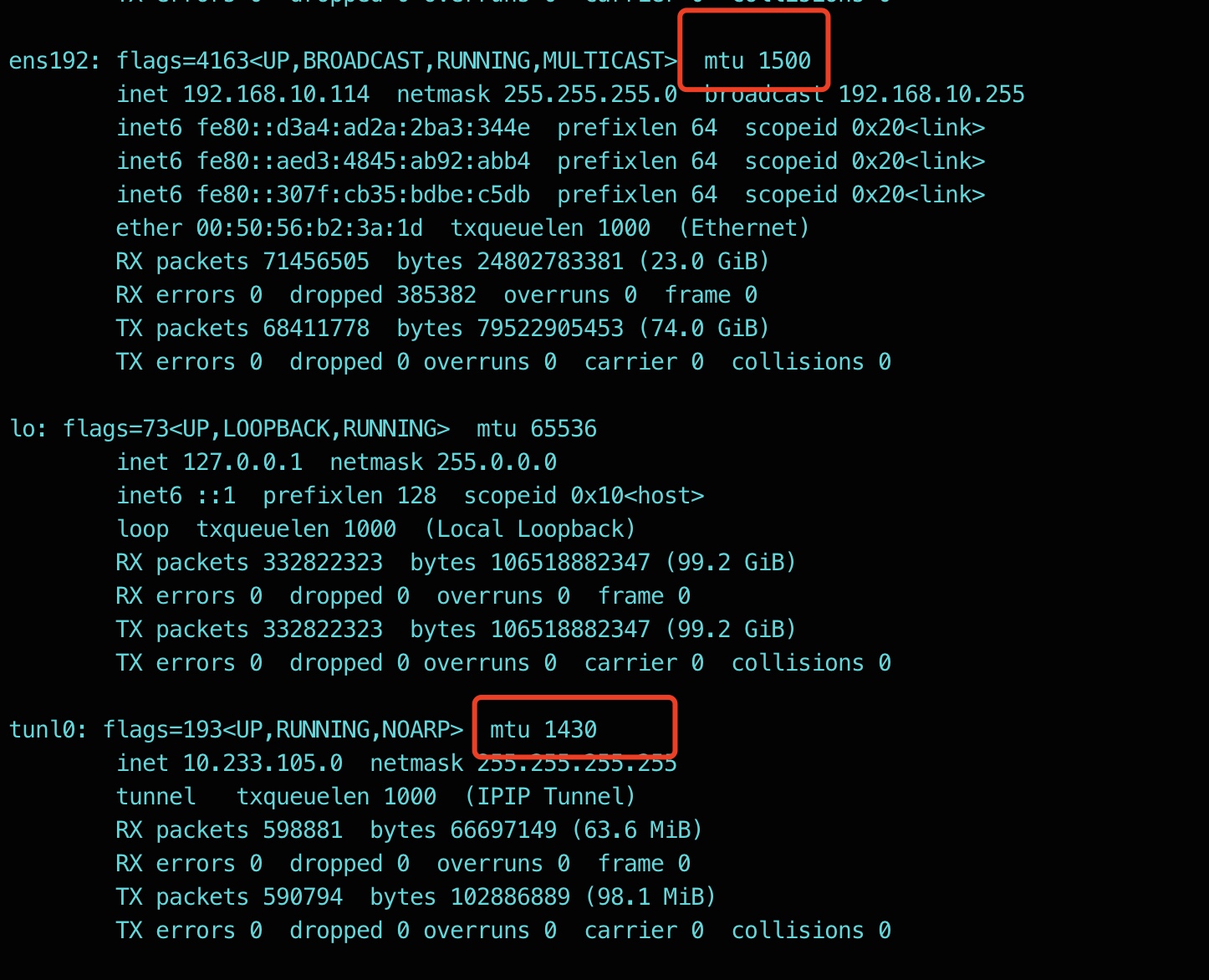
- kubectl -n kube-system edit ds calico-node
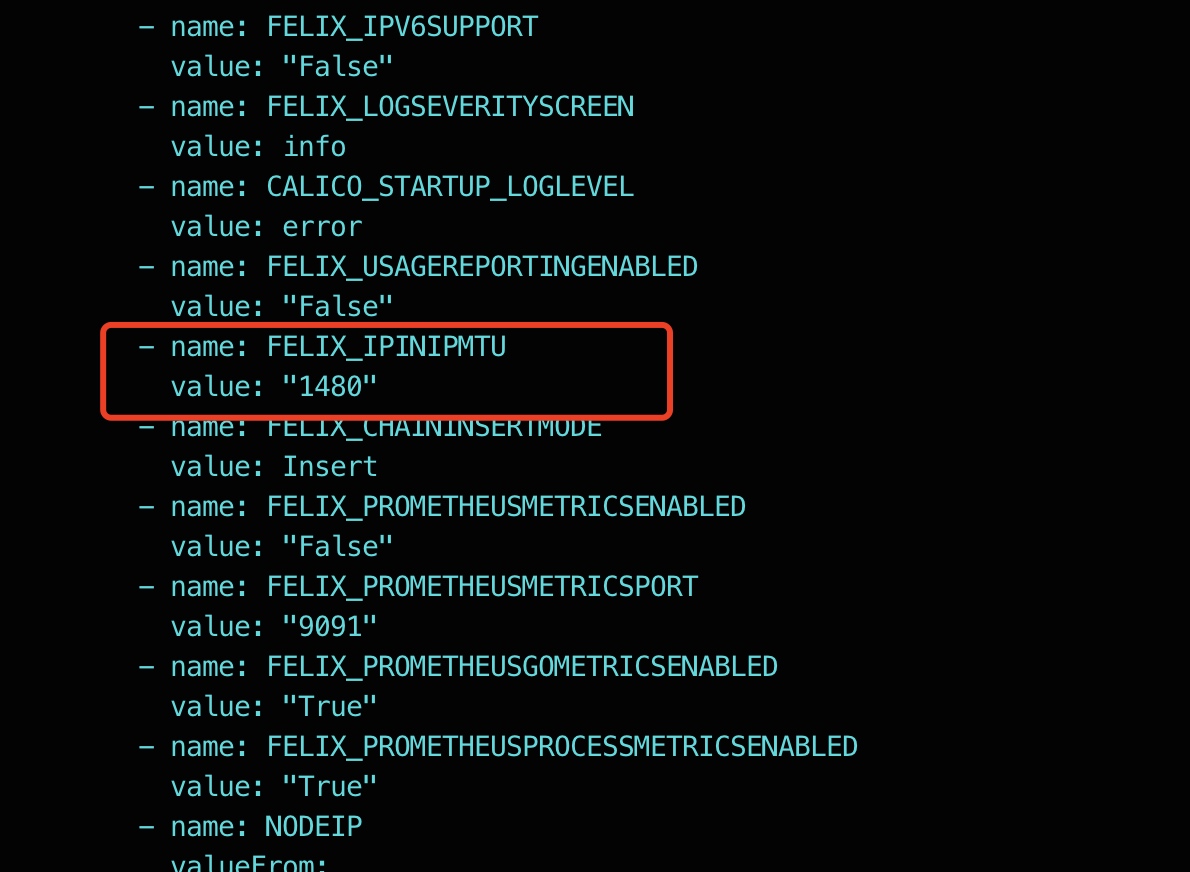
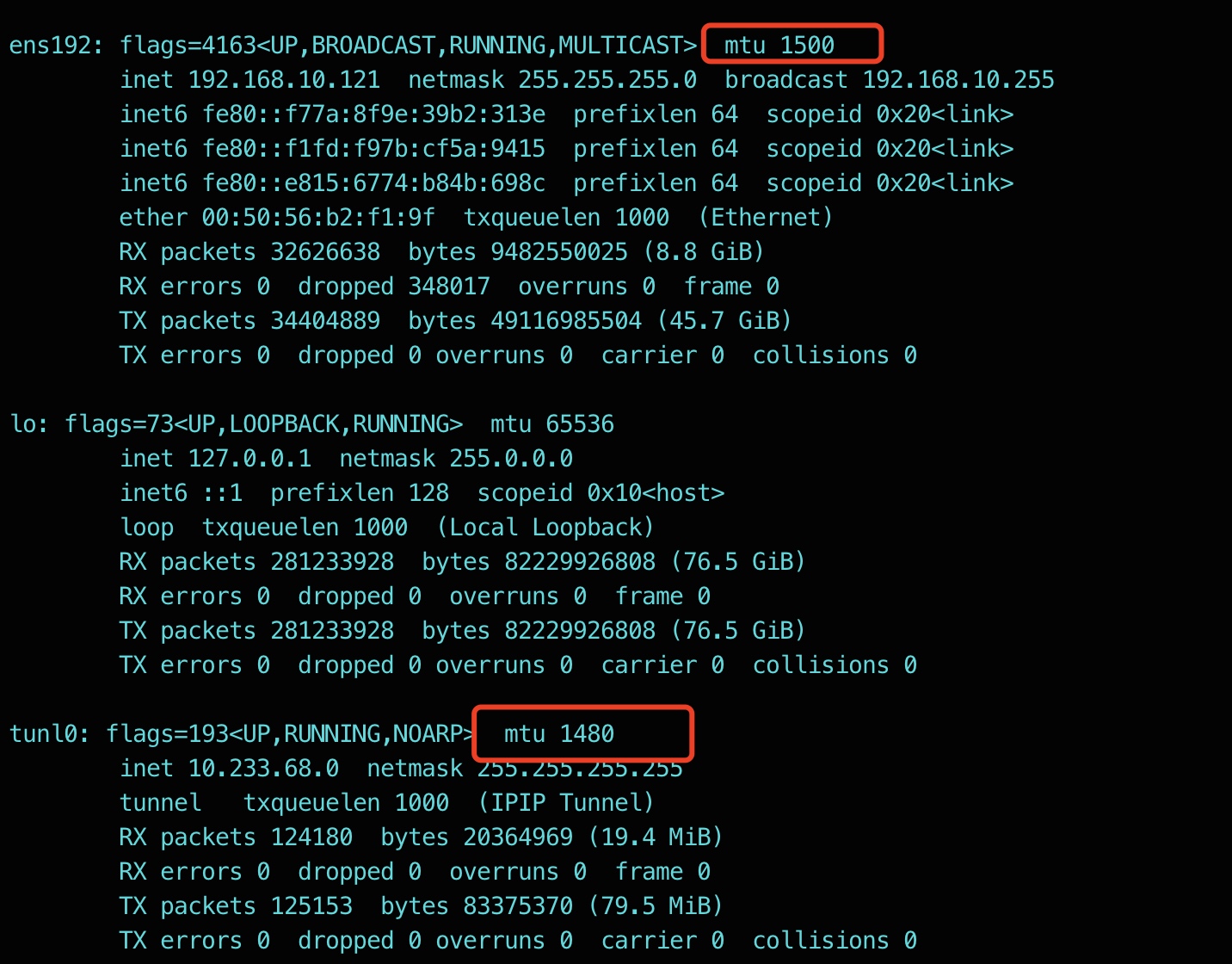
- 重启服务,发现故障依旧
- 排查过程中,也出现了,通过nacos获取的中间件地址为其他集群的地址。怀疑是机器的DNS搜索域导致的问题,注释掉集群内的搜索域,问题解决
$ cat /etc/resolv.conf
# Generated by NetworkManager
# search guoyutec.com
nameserver 8.8.8.8
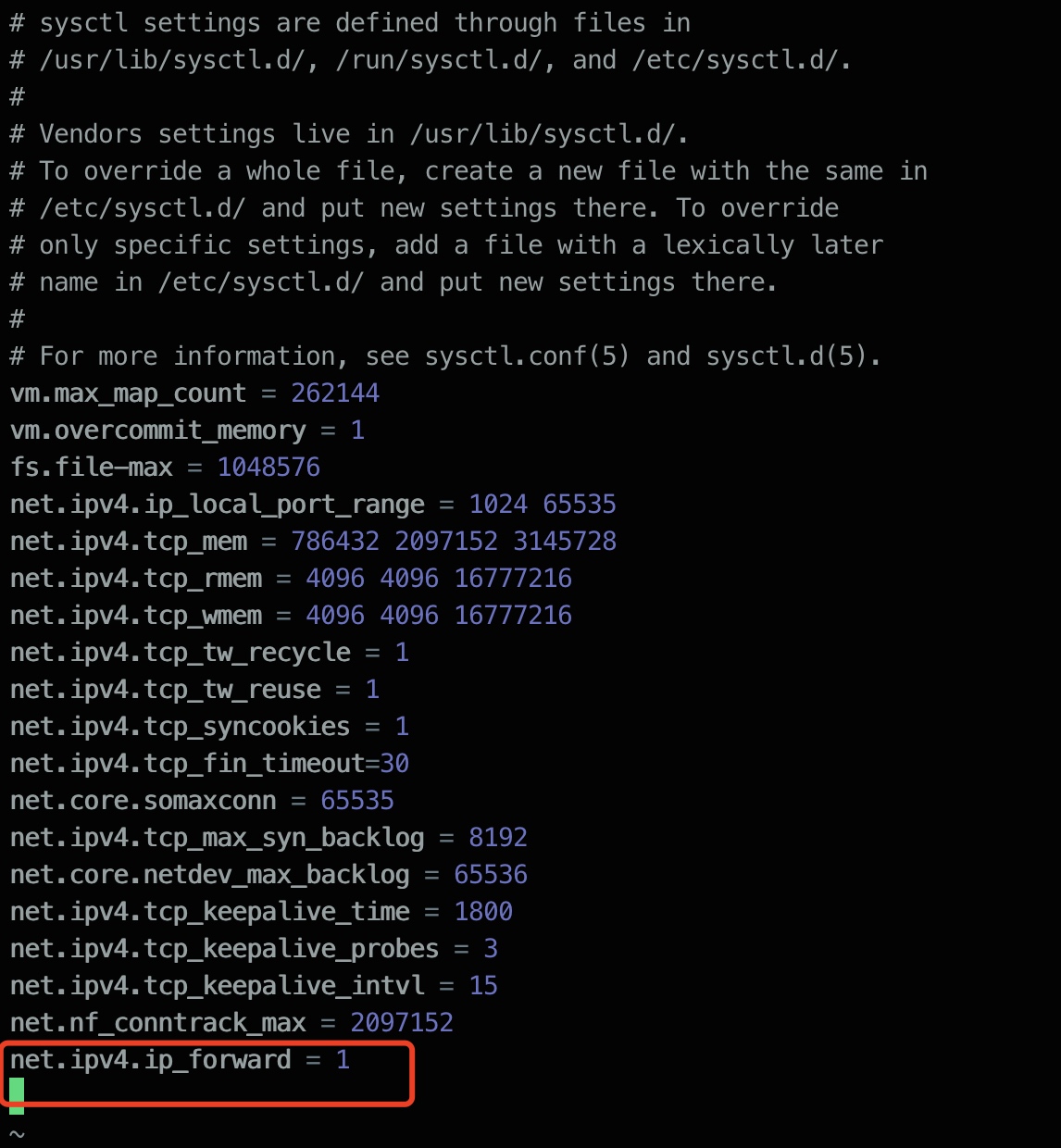
- 结合以往故障记录,由于k8s的pod均是使用的nat模式访问目标机器,怀疑目标机器未开启路由转发,登录到目标机器,查看确实未开启,追加后,重启服务器,故障依旧
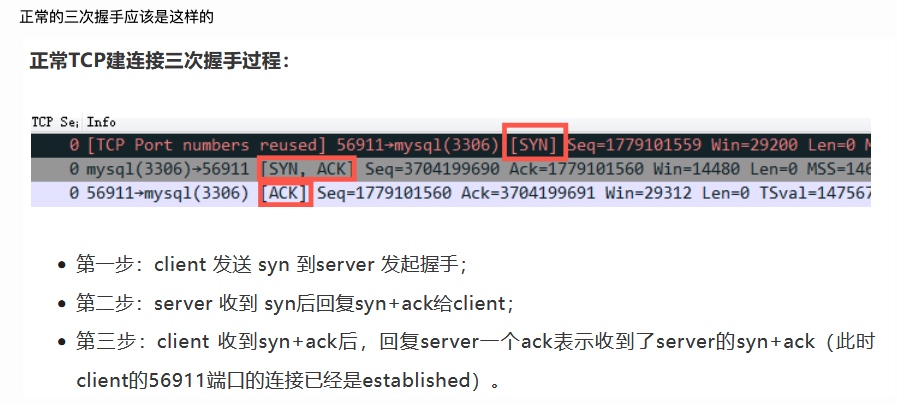
- 登录到目标主机抓包,抓包分析发现收到包之后三次握手不成功,只有客户端发送过来的SYN包,并没有服务端返回的SYN+ACK包,所以无法建立连接。
$ tcpdump -i ens192 host 192.168.10.121 and port 22 -w a.cap` $ tcpdump -i ens192 host 192.168.10.122 and port 22 -w b.cap` $ tcpdump -i ens192 host 192.168.10.123 and port 22 -w c.cap`结果类似下图

- 返回查看内核参数,发现有
net.ipv4.tcp_tw_recycle参数,以前看别人遇到过类似问题https://www.jianshu.com/p/3b8f674f577e,该参数在4.12版本内核之后被废除,发现目标节点为3.10版本内核,尝试关闭此参数,重启服务,故障恢复
故障定位
因为2.6内核以上中tcp_timestamps默认是打开的,所以当打开 tcp_tw_recycle时会导致部分通过NAT上网client无法正确连接服务器,故障表现为client发出SYN后无法收到server返回 的SYN+ACK,推荐的解决方法是关闭tcp_tw_recycle,打开tcp_tw_reuse解决TIME-WAIT过多的问题。
tcp_tw_recycle 设置为 1 会开启系统对 TIME_WAIT 状态的 socket 的快速回收。开启这个功能,系统就会存下 TCP 连接的时间戳,当同一个 IP 地址过来的包的时间戳小于缓存的时间戳,系统就直接丢包,“回收”这个 socket。这个选项同样需要开启 tcp_timestamp 才生效。 开启这个功能是有很大风险的,服务器端会根据同一个 IP 发送过来的包的时间戳来判断是否丢包,而时间戳是根据发包的客户端的系统时间得来的,如果服务端收到的包是同一出口 IP 而系统时间不一样的两个客户端的包,就有可能会丢包,可能出现的情况就是一个局域网内有的客户端能连接服务端,有的不能。具体原因是客户端处于NAT模式下,出口ip可能是同一个ip,不同客户端的发送的时间戳可能乱序,服务器会检查相同ip地址发送来过的包的时间戳是不是小于缓存的时间戳,如果不是,直接丢掉。
问题解决
# 临时解决
$ echo 0 > /proc/sys/net/ipv4/tcp_tw_recycle
# 永久解决,或升级内核到4.12+
$ vim /etc/sysctl.conf
net.ipv4.tcp_tw_recycle = 0
$ sysctl -p
参考链接: https://www.cnblogs.com/cyleon/p/16176888.html
https://www.jianshu.com/p/3b8f674f577e




