
问题现象
由于日前机房断电,导致预发布环境192.168.10.82机器磁盘文件受损,导致系统启动失败,需重新部署redis应用,并将节点迁移。
为避免IP地址的调整,新启动服务器IP地址仍为10.82。
排查记录
通过ansible-playbook进行集群的节点重新部署,发现无法成功将新节点加入到集群当中,报错信息为初始化集群失败
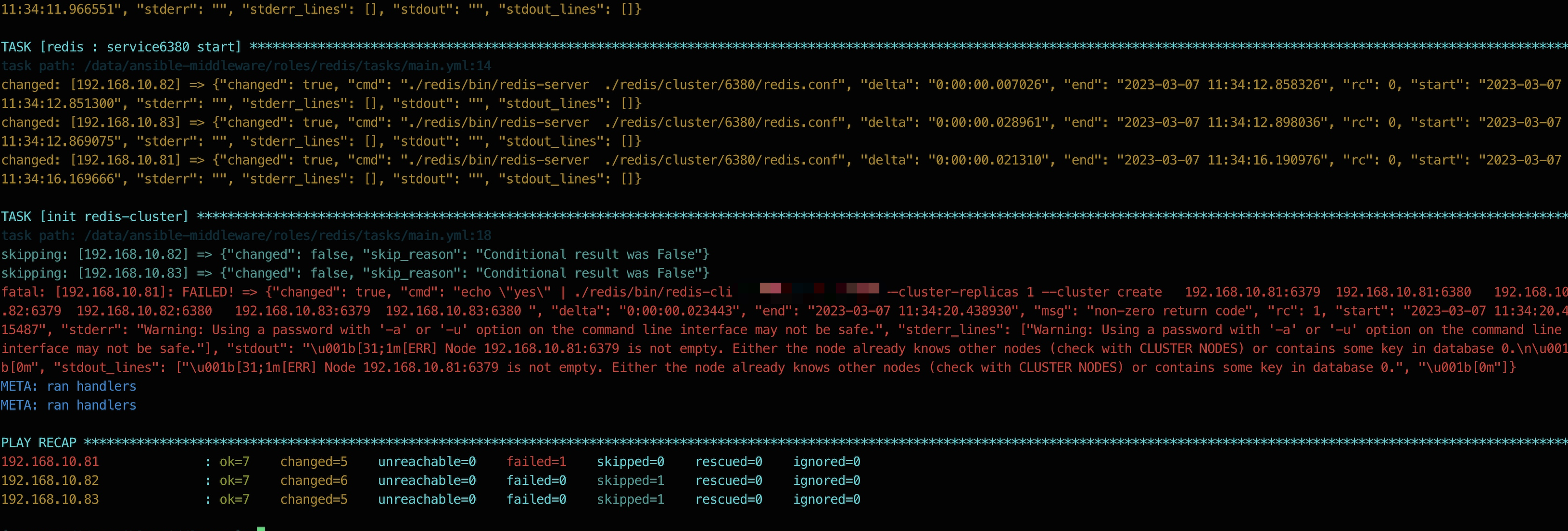
查看集群节点信息,发现原192.168.10.82上面的redis节点状态已为fail
$ redis-cli cluster nodes
53ef0b0fcbeaef543890c9c38aa1abd3d56a3009 192.168.10.81:6380@16380 slave 4bf04d8a86e1019afddafa2ce4fa16025ac6c26c 0 1678167197004 5 connected
adc2411aa619a5fff377736a42002e6d004157e8 :0@0 master,fail,noaddr - 1677798697196 1677825609046 3 disconnected
c154139de89052d4f91bbb2200d4486feabeb4b3 :0@0 slave,fail,noaddr 514fb336003c8859a5f30134fea4388e6f4ab698 1677798697196 1677825609046 4 disconnected
514fb336003c8859a5f30134fea4388e6f4ab698 192.168.10.81:6379@16379 myself,master - 0 1678167197000 1 connected 0-5460 [
4bf04d8a86e1019afddafa2ce4fa16025ac6c26c 192.168.10.83:6379@16379 master - 0 1678167197000 5 connected 10923-16383
6306f8536190ced29dd1fd465014a561d56582e9 192.168.10.83:6380@16380 master - 0 1678167198007 7 connected 5461-10922
因为原节点系统是无法登录的,所以数据方面,只能靠集群自身高可用恢复
由于原节点已经fail,尝试重新分配slot报错,需先修复集群
$ ./bin/redis-cli --cluster reshard 192.168.10.81:6379
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** Please fix your cluster problems before resharding
redis cluster 常用命令
$ ./bin/redis-cli --cluster help
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
Cluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check host:port
--cluster-search-multiple-owners
info host:port
fix host:port
--cluster-search-multiple-owners
reshard host:port
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance host:port
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-copy
--cluster-replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
执行修复操作
$ ./bin/redis-cli --cluster fix 192.168.10.81:6379
>>> Setting 11590 as STABLE in 192.168.10.83:6379
>>> Fixing open slot 14710
*** Found keys about slot 14710 in non-owner node 192.168.10.81:6379!
*** Found keys about slot 14710 in node 192.168.10.83:6379!
Set as importing in: 192.168.10.81:6379,192.168.10.83:6379
>>> Nobody claims ownership, selecting an owner...
*** Configuring 192.168.10.81:6379 as the slot owner
>>> Case 2: Moving all the 14710 slot keys to its owner 192.168.10.81:6379
Moving slot 14710 from 192.168.10.83:6379 to 192.168.10.81:6379: *** Target key exists. Replacing it for FIX.
.
>>> Setting 14710 as STABLE in 192.168.10.83:6379
>>> Fixing open slot 12417
*** Found keys about slot 12417 in non-owner node 192.168.10.81:6379!
*** Found keys about slot 12417 in node 192.168.10.83:6379!
Set as importing in: 192.168.10.81:6379,192.168.10.83:6379
>>> Nobody claims ownership, selecting an owner...
*** Configuring 192.168.10.81:6379 as the slot owner
>>> Case 2: Moving all the 12417 slot keys to its owner 192.168.10.81:6379
Moving slot 12417 from 192.168.10.83:6379 to 192.168.10.81:6379: *** Target key exists. Replacing it for FIX.
.
>>> Setting 12417 as STABLE in 192.168.10.83:6379
>>> Check slots coverage...
[OK] All 16384 slots covered.
查看集群状态 为 ok
$ ./bin/redis-cli cluster info
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
cluster_state:ok //ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:8
cluster_my_epoch:8
cluster_stats_messages_ping_sent:752727
cluster_stats_messages_pong_sent:484961
cluster_stats_messages_fail_sent:10
cluster_stats_messages_auth-ack_sent:1
cluster_stats_messages_update_sent:33
cluster_stats_messages_sent:1237732
cluster_stats_messages_ping_received:484961
cluster_stats_messages_pong_received:496686
cluster_stats_messages_fail_received:2
cluster_stats_messages_auth-req_received:1
cluster_stats_messages_received:981650
集群状态恢复后,则需要梳理一下主从关系信息,重新分配主从角色
53ef0b0fcbeaef543890c9c38aa1abd3d56a3009 192.168.10.81:6380@16380 slave 4bf04d8a86e1019afddafa2ce4fa16025ac6c26c 0 1678167197004 5 connected
adc2411aa619a5fff377736a42002e6d004157e8 :0@0 master,fail,noaddr - 1677798697196 1677825609046 3 disconnected
c154139de89052d4f91bbb2200d4486feabeb4b3 :0@0 slave,fail,noaddr 514fb336003c8859a5f30134fea4388e6f4ab698 1677798697196 1677825609046 4 disconnected
514fb336003c8859a5f30134fea4388e6f4ab698 192.168.10.81:6379@16379 myself,master - 0 1678167197000 1 connected 0-5460 // 该主节点无slave
4bf04d8a86e1019afddafa2ce4fa16025ac6c26c 192.168.10.83:6379@16379 master - 0 1678167197000 5 connected 10923-16383 // 该主节点已经有slave
6306f8536190ced29dd1fd465014a561d56582e9 192.168.10.83:6380@16380 master - 0 1678167198007 7 connected 5461-10922 // 该主节点无slave
当前集群状态为3主1从,为保证每一个master节点都有一个slave,因此我们需要将新添加的两个节点配置为slave
# 加入新节点
$ ./bin/redis-cli --cluster add-node 192.168.10.82:6379 192.168.10.81:6379 --cluster-slave --cluster-master-id 6306f8536190ced29dd1fd465014a561d56582e9
$ ./bin/redis-cli --cluster add-node 192.168.10.82:6380 192.168.10.81:6379 --cluster-slave --cluster-master-id 514fb336003c8859a5f30134fea4388e6f4ab698
加入节点之后,需要重新均衡slot,并且需要重新分配slot
$ ./bin/redis-cli --cluster rebalance 192.168.10.82:6379
# 重新分配
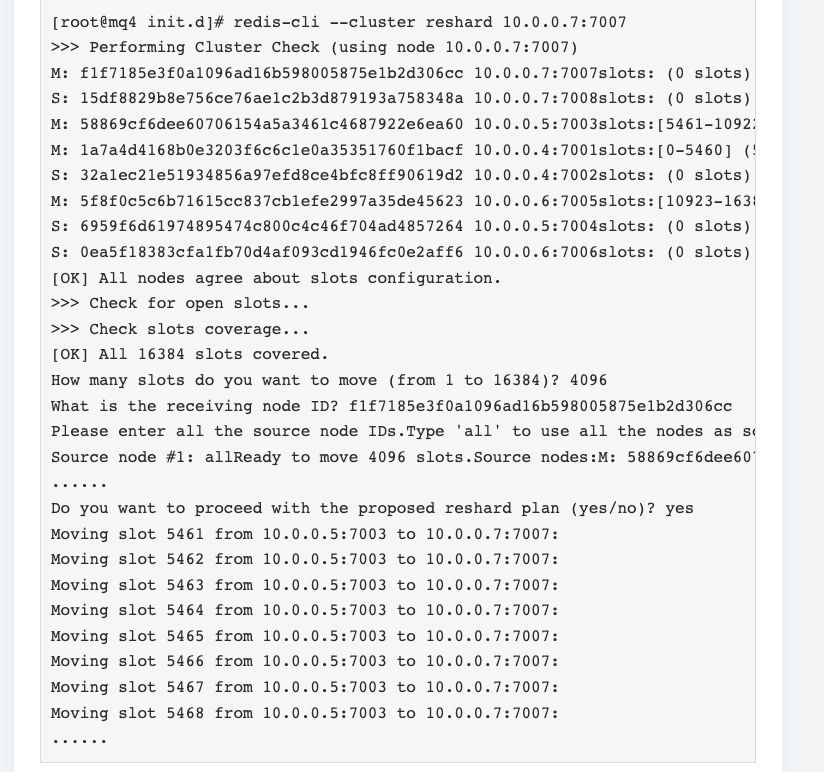
$ ./bin/redis-cli --cluster reshard 192.168.10.82:6379
集群数据量不是特别的大直接分配的16384个slot,显示信息类似下面

集群恢复,fail状态的节点直接forget即可
$ ./bin/redis-cli cluster forget adc2411aa619a5fff377736a42002e6d004157e8
OK
$ ./bin/redis-cli cluster forget c154139de89052d4f91bbb2200d4486feabeb4b3
OK





